
")

 Notícias
Notícias

O que sua voz pode dizer sobre sua saúde? Médicos experientes são capazes de detectar inúmeros sinais de que um paciente não está bem estabelecendo uma simples conversa, especialmente quando uma síndrome respiratória, tal como a provocada pelo coronavírus, dificulta a comunicação pela fala. E se conseguíssemos ensinar essa habilidade aos computadores? Será que uma solução assim seria capaz de ajudar a reduzir a intensa demanda por profissionais de saúde em um cenário de pandemia como o que estamos enfrentando?
São perguntas como essas que desafiam um grupo de pesquisadores da USP composto por especialistas de diversas áreas do conhecimento como cientistas de computação, médicos e linguistas. À primeira vista, a ideia pode parecer bastante simples, mas há muitas barreiras a serem enfrentadas na criação de uma ferramenta capaz de reconhecer automaticamente variações na voz de quem fala português, objetivo principal do projeto Sistema de Detecção Precoce de Insuficiência Respiratória por meio de Análise de Áudio (SPIRA).

Reportagem sobre o projeto foi veiculada pelo Jornal Nacional. Assista: https://globoplay.globo.com/v/8625208/programa
Coral de vozes – Para desenvolver a solução, inicialmente, os pesquisadores precisam ensinar o computador a identificar quais características têm a voz de uma pessoa saudável em contraposição ao que caracteriza a voz de alguém afetado por uma síndrome respiratória. Tal como acontece na trajetória dos médicos, que aprendem a identificar essas características a partir de suas experiências ao longo de inúmeros atendimentos a diversos pacientes, o computador também precisa de uma grande quantidade de dados para se tornar capaz de classificar adequadamente os pacientes.
Nesse caso, os dados são compostos por um verdadeiro coral de vozes e até você pode contribuir com a pesquisa doando sua voz. Para isso, basta acessar este site: https://spira.ime.usp.br/coleta. Mais de sete mil pessoas já acessaram a plataforma, gravaram três frases e contribuíram com a pesquisa. A dificuldade está em coletar as vozes dos pacientes diagnosticados com covid-19, explica o professor Marcelo Finger, do Instituto de Matemática e Estatística (IME) da USP, coordenador do projeto: “Para fazer a coleta das vozes dos pacientes, precisamos de profissionais da área de saúde capacitados, treinados e que tenham autorização para transitar pela enfermaria de um hospital que trata de pacientes infectados pelo novo coronavírus. E sabemos que, desde o princípio da pandemia, esses profissionais estão absolutamente sobrecarregados”.
Até o momento, os pesquisadores conseguiram coletar vozes de aproximadamente 200 pacientes diagnosticados com covid-19, que estão internados em dois hospitais parceiros do projeto, o Hospital das Clínicas da Faculdade de Medicina da USP e o Hospital Universitária da USP, ambos localizados na cidade de São Paulo. Para facilitar a captação do áudio dos pacientes, o doutorando Murilo Gazzola, do Instituto de Ciências Matemáticas e de Computação (ICMC) da USP, em São Carlos, desenvolveu uma ferramenta para o aplicativo de mensagens WhatsApp. Assim, o profissional de saúde pega o celular, clica no número correspondente à ferramenta, apresenta as frases ao paciente e grava a voz de cada um por meio do próprio WhatsApp. Na sequência, os áudios são enviados a uma base de dados que, automaticamente, realiza uma primeira triagem e organiza o que foi coletado.
Excesso de sons – “Quando analisamos a voz dos pacientes internados, descobrimos que havia desafios adicionais a serem enfrentados”, revela a professora Sandra Aluísio, que é orientadora de Murilo e coordena os esforços da equipe do ICMC no projeto SPIRA. “No cenário da coleta, muitos pacientes são idosos e, normalmente, estão sem os óculos. Eles não conseguem ler as frases propostas pelo estudo, que são apresentadas no celular. Então, o profissional de saúde precisa ajudá-los, soletrando as frases, o que faz com que essa outra voz também apareça nas gravações”, acrescenta a pesquisadora.
Sandra explica que, se a voz do profissional de saúde for mantida nas gravações, no momento em que os dados forem utilizados para ensinar o computador, serão produzidos resultados equivocados. Por exemplo, o computador passaria a interpretar que um fator determinante para a doença é a existência de duas vozes distintas em um mesmo áudio, pois a maioria dos áudios de pessoas infectadas terá mais de uma voz presente. Se isso acontecesse, o sistema não teria aprendido a analisar adequadamente as características que, de fato, diferenciam a voz de uma pessoa saudável do som emitido por alguém acometido por uma síndrome respiratória.
“Remover manualmente a voz dos médicos nas gravações é um trabalho muito demorado. Para agilizar essa etapa e fazer a separação das vozes de forma automática, estamos criando uma ferramenta de inteligência artificial, baseada em redes neurais artificiais”, acrescenta a professora. É especificamente a esse desafio que está se dedicando Edresson Casanova, outro doutorando do ICMC que participa do projeto e também é orientado por Sandra.
“A análise do áudio bruto é muito custosa e complexa, mesmo para as técnicas mais avançadas de inteligência artificial, devido a um problema da computação chamado de maldição da dimensionalidade dos dados. Então, em vez de treinar uma rede neural artificial com os dados brutos de áudio, que possibilitariam uma taxa menor de sucesso, tentamos usar alternativas baseadas em extrações de características e padrões contidos nesses arquivos”, diz Edresson.
O caminho encontrado pelo doutorando consistiu em, literalmente, tornar a voz visível para o computador (confira as imagens). Assim, ele conseguiu empregar técnicas de visualização computacional – que já foram amplamente testadas e estão disponíveis – para separar as vozes. Depois, é só voltar a transformar a imagem (que agora representa apenas uma voz) em áudio e pronto. Esse método de separação está, atualmente, sendo testado a partir de um banco com mil horas de vozes em inglês, que permitiu gerar vozes sobrepostas. “Ainda não há disponível uma base de fala aberta tão grande para o português”, ressalta Sandra.
Ela diz ainda que há muitos ruídos nas gravações dos pacientes hospitalizados, relacionados especialmente ao som dos equipamentos que são utilizados no local. Por isso, a equipe está estudando duas possíveis abordagens: filtrar o ruído das gravações usando técnicas de inteligência artificial ou inserir esses mesmos ruídos nas gravações dos participantes saudáveis. Adotar uma dessas medidas evitará, tal como no caso da separação das vozes, que o sistema computacional realize uma interpretação equivocada dos dados e considere o ruído como um fator determinante para diagnosticar uma síndrome respiratória.
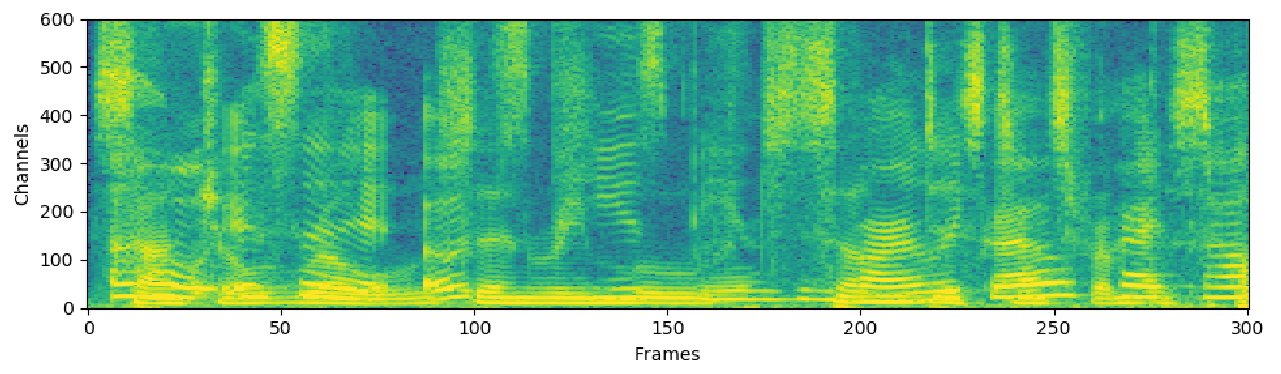
Imagem mostra um espectrograma gerado pelo computador a partir de um arquivo de áudio com duas vozes sobrepostas.
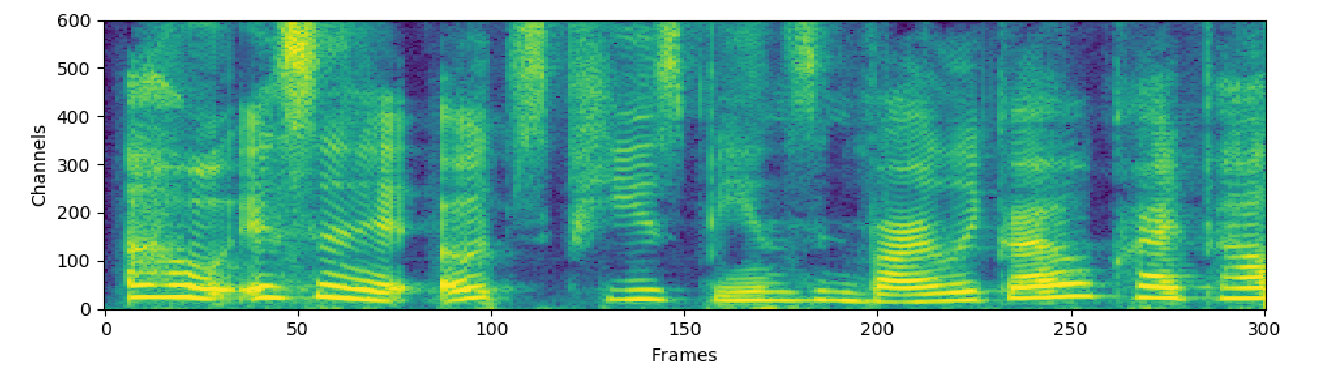
Já essa imagem é um espectrograma que representa um áudio em que uma das vozes já foi extraída.
Conhecimento em construção – “Esse é um projeto de pesquisa com risco porque pode não dar certo. De repente, não vamos conseguir criar uma ferramenta que consiga identificar sinais de insuficiência respiratória com uma precisão aceitável”, pondera o coordenador do SPIRA. De qualquer forma, os pesquisadores sabem que as descobertas que surgirem na jornada têm potencial para, futuramente, serem aplicadas em inúmeros outros campos como, por exemplo, na criação de sistemas de reconhecimento automático de voz para o português e no aprimoramento de assistentes virtuais.
A equipe do projeto é coordenada também por duas professoras da Faculdade de Medicina da USP – Anna Sara Levin Shafferman e Ester Cerdeira Sabino – e conta, ainda, com a participação de mais quatro pesquisadores: Arnaldo Cândido Júnior, da Universidade Tecnológica Federal do Paraná; Flaviane Fernandes Svartman, da Faculdade de Filosofia, Letras e Ciências Humanas da USP; Alfredo Goldman e Marcelo Gomes de Queiroz, ambos do IME; além dos alunos de pós-graduação Augusto Cesar de Camargo, Pedro Leyton Pereira, Renato Cordeiro e Thatiane Rosa, todos vinculados ao IME.
Os estudos realizados por esse grupo multidisciplinar fazem parte de uma ampla área de pesquisa em inteligência artificial que está em franca expansão no mundo: o processamento de linguagem natural. “Estamos abrindo uma frente na pesquisa sobre o emprego da voz para fazer diagnóstico de problemas variados. Inicialmente, estudamos a insuficiência pulmonar por causa do contexto em que vivemos. Mas há outras doenças que podem se manifestar pela voz como alterações nas pregas vocais, problemas cardíacos, pressão alta e ataques de ansiedade”, explica Finger.
“Enfim, no momento, estamos concentrados na detecção da síndrome respiratória, mas com o que a gente conseguir aprender nesse contexto e com a identificação dos limites das técnicas de inteligência artificial, será possível construir outras soluções”, reforça o professor. Para ele, empreender um projeto da envergadura do SPIRA, que está na fronteira do conhecimento, não seria possível se não houvesse a infraestrutura de pesquisa existente nas três universidades públicas paulistas e na FAPESP. Que essa infraestrutura possa sair fortalecida da pandemia e as vozes dos pesquisadores sejam cada vez mais ouvidas.

Já foram coletadas vozes de aproximadamente 200 pacientes diagnosticados com covid-19, que estão internados em dois hospitais parceiros do projeto, o Hospital das Clínicas da Faculdade de Medicina da USP e o Hospital Universitária da USP. (crédito da imagem: USP Imagens)
Texto: Denise Casatti – Assessoria de Comunicação do ICMC-USP
Saiba mais
Sobre o SPIRA: spira.ime.usp.br
Doe sua voz: spira.ime.usp.br/coleta
Live Ciência USP: descobrindo o coronavírus pela pela voz e pela saliva
Reportagem sobre o projeto veiculada pelo Jornal Nacional
